Note sur la syntaxe et le fonctionnement des fichiers .ld et du linker “ld”, pour une utilisation orientée programmation embarqué.
Dans les grandes lignes, le linker script (fichier .ld) permet d’indiquer au programme “ld” comment le contenu des fichiers objet (.o) doit être assemblé pour créer le fichier ELF.
Dans le cas qui m’intéresse - les firmwares ciblant des microcontrôleurs - le fichier elf sera soit converti en fichier hexa ou binaire soit directement utilisé par openocd pour programmer le MCU.
Un exemple de linker script est disponible ici sample.ld.
Architecture du fichier .ld
Les fichiers .ld sont de simples fichiers texte. On peut y écrire des commentaires via la syntaxe /* mon commentaire */.
Pour indiquer à l’éditeur de liens comment agencer les objets en mémoire, nous avons à disposition quelques mots-clés (liste non exhaustive, je me contente ici des mots-clés qui me sont utiles):
MEMORYDéclare les zones mémoire utilisables, leurs adresses et leurs tailles.SECTIONSPermet de déclarer les différentes sections, où les ranger et dans quel ordre..Le point n’est pas un mot-clé à proprement parler mais une variable spéciale. Elle enregistre la dernière adresse mémoire utilisée durant l’assemblage des objets. Elle nous permet donc de récupérer la position actuelle de *l’assemblage en mémoire:_myvar = .. Elle permet aussi de forcer la position d’une section:. = 0xFF(semblable à l’instructionAT(x)).KEEPIndique à l’éditeur de liens de garder cette section même si elle est vide. Ce mot-clé a toute son importance lorsque l’on passe l’option--gc-sectionsà l’éditeur.AT(x): Est un attribut de section (optionnel) qui permet de spécifier l’adresse à laquelle doit être placé la section.> Y AT > X: Cette utilisation deATdiffère de la précédente. Dans ce cas, on l’utilise pour indiquer la zone mémoire de stockage (Y) et la zone mémoire dans laquelle la section doit être chargée (X).ALIGN(x)spécifie l’alignement en mémoire, x étant le nombre d’octetsNOLOADIndique au sein du fichier ELF que la section n’a pas besoin d’être chargée au démarrage du système. Ce mot-clé ne semble pas pertinent dans notre cas puisque le démarrage n’est pas fait à partir du fichier ELF mais cela nous permet de décrire les sections.LOADADDRpermet de récupérer l’adresse d’une section en mémoire.PROVIDEIl y a deux manières de définir un symbole, soit par un assignement, soit viaPROVIDE.PROVIDEpermet de définir le symbole s’il n’est pas déjà défini dans les fichiers objets à assembler.PROVIDE_HIDDENPermet de définir une variable mais sans l’exporter ; donc définir une variable locale plutôt que globale.ASSERTassertion classique permet de déclencher une erreur si le résultat du test est égal à zéro.SIZEOFpermet de récupérer la taille d’une section.SORTpermet de trier une liste
De manière naïve, nous pouvons dire que ces scripts sont découpés en trois parties:
- La déclaration des variables Via l’assignation
=ouPROVIDE, on peut assigner une valeur à une variable que l’on pourra réutiliser plus tard dans le script. Dans notre exemple, on s’en sert pour définir la taille maximale de la stack. - La description de la mémoire du périphérique. Grâce au mot-clé
MEMORY, on indique l’adresse des zones mémoire à utiliser et leurs tailles. - La description de comment ranger le code en mémoire
Description de la mémoire
Cette section permet de décrire la zone mémoire utilisable. Dans notre exemple, nous avons trois zones, la RAM, le BOOTLOADER et la FLASH.
FLASH_SIZE = 0x10000000
RAM_SIZE = 0x30000
MEMORY{
FLASH(rx) : ORIGIN = 0x00000000, LENGTH = FLASH_SIZE
RAM(rwx) : ORIGIN = 0x20000000, LENGTH = RAM_SIZE
}
On remarque que la déclaration de variable et leur assignement nous permet de facilement séparer une même mémoire physique en deux mémoires virtuelles (BOOTLOADER et FLASH).
La déclaration des zones mémoire nous permet aussi d’indiquer les droits d’accès pour chacune de ces zones.
La gestion des sections
Le mot-clé SECTIONS{} permet de définir plus finement l’organisation du code dans les différentes zones mémoire.
La table des vecteurs d’interruption
Dans le cas d’un MCU basé sur l’architecture ARM Cortex-M, la première section doit être la table des vecteurs d’interruption.
Nous allons donc commencer le script avec:
SECTIONS{
/* force la position à l'adresse relative 0 */
. = 0x0;
.vectors : {
/* indique que les données doivent être
alignées sur 4 octets */
. = ALIGN(4);
KEEP(*(.vectors))
} > BOOTLOADER;
}
Attention, il ne faut pas oublier d’ajouter __attribute__ ((section(".vectors"))) à la déclaration de la table des vecteurs d’interruption afin de spécifier son lieu de stockage.
En ce qui concerne l’appellation des objets et des sections, GCC génère trois formes de “section” différentes:
mysection: la classiquemysection.mafonctionmysection.mydata: générée automatiquement si l’on compile le programme avec les options-ffunction-sectionsou-fdata-sections. Ces options permettent de générer une section par fonction/data. Cela peut être pratique pour placer précisément une donnée ou une fonction dans une zone particulière : par exemple en SRAM pour réduire les temps d’accès.gnu.linkonce.{type}.{nom}: liée au Vague Linkage Cette section ne semble concerner que le code C++
Les sections usuelles
Les sections usuelles servent à stocker le code et les variables. On y retrouve :
.text: le code.rodata: les données en lecture seule.data: les données en lecture/écriture initialisées avec une valeur.bss: les données en lecture/écriture non initialisées
Notons que les sections .data et .bss doivent être, respectivement, copiées et initialisées en RAM au démarrage du MCU. Dans notre cas de figure, cette opération est réalisée dans la fonction de démarrage (fonction appelée par l’interruption de Reset).
Ce sont les quatre sections que l’on retrouve systématiquement. Nous pouvons aussi y ajouter nos propres sections pour stocker une partie spécifique du programme à un emplacement donné.
Par exemple on pourrait vouloir que certaines fonctions soient exécutées depuis une autre zone mémoire (ex: SRAM) afin d’optimiser la vitesse d’exécution. On aurait alors le linker script suivant:
SECTIONS{
.text : {
} > FLASH
.data : {
} > RAM
.bss : {
} > RAM
.superImportanteSection {
speed_function.o
} > SRAM AT > FLASH
}
L’indication > SRAM AT > FLASH permet d’indiquer que ces données sont stockées en FLASH mais doivent être chargées en SRAM au démarrage. Attention, ce n’est pas fait automatiquement : il faut adapter la fonction de démarrage (dans le cas d’un MCU) pour copier la section (cf: bss et data).
Les sections spécifiques
On retrouve ici les sections utilisées par le compilateur pour stocker les constructeurs et destructeurs d’objets (new et delete en C++ et __attribute__((constructor)) en C). N’utilisant pas le C++ en embarqué, l’étude de ce fonctionnement n’a pas été poussée.
Ce que j’ai pu en comprendre, c’est que ces sections sont utilisées par le compilateur pour stocker des pointeurs de fonction permettant d’initialiser/déinitialiser des variables.
Ces fonctions sont appelées via __libc_init_array durant la phase de démarrage et via __libc_fini_array à la fin de l’exécution (ce qui n’arrive jamais en embarqué). (cf picolibc).
Les sections d’initialisation et destruction sont:
- preinit_array : générer par le compilateur pour les classes C++ (vtable) (je n’ai pas creusé davantage)
- init_array : les fonctions avec l’attribut constructor. ATTENTION les constructeurs sont initialisés avec un ordre de priorité. Donc init_array doit être trié avec SORT.
- fini_array : les fonctions avec l’attribut destructeur
- ctors: déprécié
- dtors: déprécié
Les sections ARM Debug
Pour pouvoir utiliser la fonction backtraces en debug, if faut fournir deux sections:
- exidx : qui contient l’index permettant de décoder la stack
- extab : qui contient le nom des sections contenant des infos sur les exceptions en cours ??? pas clair
Ressource:
Il semble que ces sections permettent d’analyser et restaurer la stack sans passer par le frame_pointer (fp). Ils parlent - sur so - d’utilisation pour les fonctions asynchrones. Freertos need it ?
Organisation de la RAM
Une des raisons m’ayant poussé à comprendre plus finement le fonctionnement des scripts de liens et de leurs éditeurs est de pouvoir modifier l’agencement de la RAM pour éviter que la pile déborde sur la stack ou que la stack descende sur la pile. Ces bugs sont particulièrement pénibles à résoudre…
L’idée ici est d’organiser la RAM de la manière suivante:
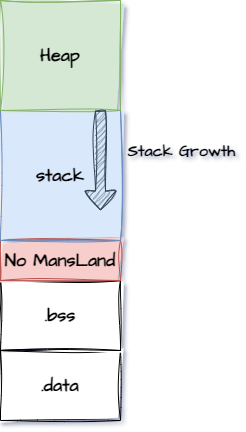
Ainsi, la pile, qui est descendante sur ARM Cortex-M, viendra déborder sur la section “NoMansLand”. Donc en configurant le périphérique de protection mémoire (MPU) correctement, on pourra “normalement” détecter le débordement de la stack.
Idem pour la HEAP, qui elle est croissante et viendra déborder sur une adresse non accessible en écriture et nous permettra de détecter le dépassement rapidement.
Cet article explique clairement l’intérêt de cette configuration.
Mold
J’ai voulu voir s’il était possible de remplacer ld par mold mais mold ne supporte qu’un tout petit sous-ensemble de la syntaxe des linker-scripts. Il est donc impossible de l’utiliser pour l’embarqué en none-eabi.